事务交易安全
交易(Transaction),是所有数据库的基础概念。 基本上来说,一个交易指的是,一系列的执行步骤包裹在一起,其结果只有全部成功或全部失败两种情况的操作行为。
在 PostgreSQL 中,所谓的交易,是以 SQL 的 BEGIN 及 COMMIT 两个指令相夹的过程。 所以我们前述的银行交易实际上会像这样:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
-- etc etc
COMMIT;
如果在交易的过程之中,我们决定不要完成交易(也许我们发现 Alice 的帐户余额不足),我们可以使用 ROLLBACK 指令来取代 COMMIT,那么所有数据的变更都会取消。
PostgreSQL 一般将每一个 SQL 指令都视为一个交易来执行。 如果你并没有使用BEGIN指令,那么每一个个别的指令就会隐含BEGIN先行,然后如果成功的话,COMMIT也自动执行。 一系列被 BEGIN 和 COMMIT 包夹的区域,有时候就称为交易区块。
还有一种交易的控制更为细致,就是使用交易储存点(savepoint)。 交易储存点允许你可以选择性地取消部份交易,而只成交剩下的部份。 使用 SAVEPOINT 指令定义一个交易存储点之后,你可以使用 ROLLBACK,回复该交易状态到交易储存点。
假设我们从 Alice 的帐号提出了 $100.00,然后存入了 Bob 的账户之中,随后又发现应该要存到 Wally 的账户。 我们可以使用交易存储点来完成这个过程:
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
ROLLBACK TO是唯一能够控制交易区块执行流程的方式,当系统产生错误时,可以缩小回复的范围,而不是只能全部回复再执行。
窗函数
窗函数(window function)提供了在一个数据表中,进行数据列与数据列之间的关连运算。
然而,窗函数并无法像汇总函数一样,把多个数据列运算合并为单一数据列的结果。 取而代之的是,这些数据列仍然是分开并列的状态。 在这样的情境下,窗函数能让查询结果的每一个资料列,都得到更多信息。
这里有一个列子,试着比较每一个员工他的薪资及他的部门平均薪资的情况:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)
前面三个字段是由数据表 empsalary 直接取得,每一个数据列就是该数据表的每一个数据列列。 而第四个字段则呈现整个数据表中,与其 depname 相同的平均薪资。 (这实际上就是由非窗函数的 avg 汇总而得,只是 OVER 修饰字让它成为窗函数,透过「窗」的可见范围做计算。 )
窗函数都会使用 OVER 修饰字,然后紧接着窗函数及其参数。 OVER 区段需要确切指出如何分组要被窗函数计算的数据列。 PARTITION BY 在 OVER 中,意思是要以 PARTITION BY 之后的表示式来分组或拆分数据列的数据。 对于每一个数据列而言,窗函数的结果是,通过所有和该数据列相同分组的数据,共同运算而得。
你也可以控制栏被窗函数处理的次序,透过在 OVER 中加入 ORDER BY。 (窗内的 ORDER BY 不见得需要对应到数据行输出的次序)例子如下:
SELECT depname, empno, salary,
rank() OVER (PARTITION BY depname ORDER BY salary DESC)
FROM empsalary;
depname | empno | salary | rank
-----------+-------+--------+------
develop | 8 | 6000 | 1
develop | 10 | 5200 | 2
develop | 11 | 5200 | 2
develop | 9 | 4500 | 4
develop | 7 | 4200 | 5
personnel | 2 | 3900 | 1
personnel | 5 | 3500 | 2
sales | 1 | 5000 | 1
sales | 4 | 4800 | 2
sales | 3 | 4800 | 2
(10 rows)
如上所示,rank 函数为每个有使用 ORDER BY 的分组,标记一系列数字的次序。 rank 不需要特定的参数,因为它标记的范围一定是整个 OVER 所涵盖定的范围。
窗函数所计算的范围,是一个虚拟数据表的概念,是由 WHERE、GROUP BY、HAVING、或其他方式虚拟出来的。 举例来说,当某个数据列被 WHERE 过滤掉时,它也不会被任何窗函数看见。 一个查询中可以包含多个窗函数,透过不同 OVER 修饰字的指定,将资料做不同观点的处理。 但他们都会在一个相同的虚拟数据表中进行处理。
还有另一个窗函数相关的重要概念:对于每一个数据列来说,它会在分组中还有个分组,另称作窗框(window frame),有一些窗函数只对窗框里的数据列进行处理,而不是整个分组。 默认的情况是,如果 ORDER BY 被指定了,以 ORDER BY 排序后,那么窗框的范围就是从分组的第一列到该列为止,而在那之后资料列的值都会相同。 当 ORDER BY 被省略的时候,默认窗框的范围就是整个分组( 有一些选项可以通过其他方式定义 window frame,但本文并不会涵盖它们。 有关详细信息,请参阅4.2. 參數表示式 - PostgreSQL 正體中文使用手冊。 )。 下面是使用 sum 的例子:
SELECT salary, sum(salary) OVER () FROM empsalary;
salary | sum
--------+-------
5200 | 47100
5000 | 47100
3500 | 47100
4800 | 47100
3900 | 47100
4200 | 47100
4500 | 47100
4800 | 47100
6000 | 47100
5200 | 47100
(10 rows)
上面可以看到,因为在 OVER 里面没有 ORDER BY,窗框就等于整个分组,甚至因为没有 PARTITION BY,所以等于整个数据表。 换句话说,每一个数据列总和都是整个数据表的总计,所以我们在每一个数据列中都得到相同的结果。 但如果我们加入了 ORDER BY 之后,结果将会不同:
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum
--------+-------
3500 | 3500
3900 | 7400
4200 | 11600
4500 | 16100
4800 | 25700
4800 | 25700
5000 | 30700
5200 | 41100
5200 | 41100
6000 | 47100
(10 rows)
这里的总和就是从第一笔(最小),加计到每一列,包含薪资相同的每一列(注意薪资相同的)。
窗函数只允许出现在SELECT的输出列表及ORDER BY子句里,在其他地方都是被禁止的,像是GROUP BY,HAVING,WHERE等区段。 这是因为窗函数在逻辑上,都是在他们处理完之后才进一步处理数据的。 也就是说,窗函数是在非窗函数之后才执行的。 这意指在窗函数中使用非窗函数是可以的,但反过来就不行了。
如果有一个需要在窗函数处理完再进行过滤或分组的查询的话,你可以使用子查询。 举列来说:
SELECT depname, empno, salary, enroll_date
FROM
(SELECT depname, empno, salary, enroll_date,
rank() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos
FROM empsalary
) AS ss
WHERE pos < 3;
上面的查询只会显示内层查询的次序(rank)小于 3 的数据。
当一个查询使用了多个窗函数的话,它就会分别使用 OVER 子句来描述,但如果相同的分组方式要被多个函数所引用的话,就重复了,也容易出错。 这种情况可以使用 WINDOW 子句来取一个别名,来取代 OVER。 举个例子:
SELECT sum(salary) OVER w, avg(salary) OVER w
FROM empsalary
WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
继承
让我们创建两个数据表:cities 和 capitals。 很自然地,首都(capitals)也是城市(cities),所以你希望有个方式,可以在列出所有城市时,同时也包含首都。 如果你真的很清楚的话,你可以建立如下的结构:
CREATE TABLE capitals (
name text,
population real,
altitude int, -- (in ft)
state char(2)
);
CREATE TABLE non_capitals (
name text,
population real,
altitude int -- (in ft)
);
CREATE VIEW cities AS
SELECT name, population, altitude FROM capitals
UNION
SELECT name, population, altitude FROM non_capitals;
这样的查询结果会是正确的,不过它有点不是很漂亮,当你需要更新一些资料的时候。
有一个更好的方法是这样:
CREATE TABLE cities (
name text,
population real,
altitude int -- (in ft)
);
CREATE TABLE capitals (
state char(2)
) INHERITS (cities);
在这个例子中,capitals 继承了 cities 的所有字段(name, population, altitude)。 字段 name 的数据类型是文本类型(text),是一个 PostgreSQL 内置的数据类型,它允许字符串长度是动态的。 然后宣告 capitals 另外多一个字段,state,以呈现它是属于哪一个州。 在 PostgreSQL,一个数据表可以继承多个其他的数据格。
举个例子,下面的查询可以找出所有的城市名称,包含各州的首都,而其海拔高过于500英呎以上:
SELECT name, altitude
FROM cities
WHERE altitude > 500;
//结果
name | altitude
-----------+----------
Las Vegas | 2174
Mariposa | 1953
Madison | 845
(3 rows)
另一方面,下面的查询可以列出非首都的城市,且其海拔在 500 英呎以上:
SELECT name, altitude
FROM ONLY cities
WHERE altitude > 500;
//结果
name | altitude
-----------+----------
Las Vegas | 2174
Mariposa | 1953
(2 rows)
这里的「ONLY」(cities之前),指的是这个查询只要在数据表 cities 上就好,不包含继承 cities 其他资料表。 这里许多我们都已经讨论的指令 —SELECT、UPDATE、DELETE—都支持ONLY这个修饰字。
SQL查询语言
SQL语法
SQL 语法包含一连串的命令,命令是由一系列的指示记号所组合而成,以分号结尾。
识别项和关键字
数据库系统不能使用长度超过 NAMEDATALEN -1 的识别项; 太长的名称仍然可以在命令中被输入,但会被截断。 默认上,NAMEDATALEN 的设定是 64,所以最长的识别项名称长度是 63 字节。 如果这个限制会造成困扰的话,你也可以调整 NAMEDATALEN 的编译值,它的设定在 src/include/pg_config_manual.h 文件中。
关键词和无引号标识项都是不分大小写的,所以:
UPDATE MY_TABLE SET A = 5;
等同于:
uPDaTE my_TabLE SeT a = 5;
有一种写法很常使用,就是把关键字用大写表示,而识别项名称使用小写,例如:
UPDATE my_table SET a = 5;
它的形式就是以双引号括住的任何字符串。 受限制的识别项,就一定是识别项,不会是关键词。所以,「“select”」就会被识别为名称为「select」的表格或字段,而无引号的 select 就会被视为是关键词,也可能会产生解译错误,如果刚好用在可能是表格或字段名称的位置上的话。
UPDATE "my_table" SET "a" = 5;
引号识别项可以包含任何字符,除了字符码为 0 的字符以外。 (要包含双引号字符的话,请使用连续两个双引号。 )
常数
在 SQL 中,所谓的字串常数,指的是用单引号括住的任意字符串列,例如:’This is a string’。 如果在字符串常数内需要有单引号的话就使用连续两个单引号,例如:’Dianne’’s horse’。 注意这不是双引号,是两个单引号。
两个字串常数如果只用空白及至少一个换行符号所分隔的话,那个它们会被连在一起,和写成一个字符串是一样的。 举例来说:
SELECT 'foo'
'bar';
//等同於:
SELECT 'foobar';
//但如果是這樣:語法上就不正確了。
SELECT 'foo' 'bar';
下面是一些合法数值常数的例子:
42 3.5 4. .001 5e2 1.925e-3
任意类型的常数,可以使用下列的语法来表示:
type 'string'
'string'::typel
CAST ( 'string' AS type )
运算子
一个运算子最长可以是 NAMEDATALEN - 1(默认为 63 个字符),除了以下的字符之外:
- * / <> = ~ ! @ # % ^ & | ` ?
还有一些运算符的限制:
- 一个运算子最长可以是 NAMEDATALEN - 1(默认为 63 个字符),除了以下的字符之外:
- * / <> = ~ ! @ # % ^ & | ` ?
当使用非 SQL 标准的运算子时,你通常需要在相隣的运算子间使用空白以免混淆。 举例来说,如果你已经定义了一个左侧单元运算子 @,你就不能使用 X*@Y,必须写成 X* @Y,以确保 PostgreSQL 可以识别为两个运算子,而不是一个。
特殊字符
有一些字符并不是字母型态,而具有特殊意义,但并非运算子。 详细的说明请参阅相对应的语法说明。 本节仅简要描述这些特殊字符的使用情境。
- 钱字号($)其后接着数字的话,用来表示函数宣告或预备指令的参数编号。 其他的用法还有识别项的一部份,或是钱字引号常数。
- 小括号(())一般用来强调表达式并且优先运算。 还有某些情况用于表示某些 SQL 指令的部份的必要性。
- 中括号([])用于组成阵列的各个元素。 详情请参阅 8.15 节有关于阵列的内容。
- 逗号(,)用于一般语法上的结构需要,来分隔列表中的单元。
- 分号(; )表示 SQL 指令的结束。 它不能出现在指令中的其他位置,除非是在字串常数当中,或是引号识别项。
- 冒号(:)用在取得阵列的小项。 (参阅 8.15 节)在某些 SQL 分支(篏入式 SQL 之类的)中,冒号用来前置变量名称。
- 米字号(*)用来表示表格中所有的字段,或复合性的内容。 它也可以用于函数宣告时,不限制固定数量的参数。
- 顿号(.)用在数值常数之中,也用于区分结构、表格、及字段名称。
注解
注解是以连续两个破折号开头,一直到行结尾的字符串。 例如:
-- This is a standard SQL comment
另外,C 语言的注释语法也可以使用:
/* multiline comment
* with nesting: /* nested block comment */
*/
运算优先级
Table 4.2 列出在 PostgreSQL 中,运算子的运算优先权及运算次序。 大多数的运算子都是相同的运算优先权,并且是左侧运算。 这些优先级与次序是撰写在解译器的程序当中的。
你有时候需要加上括号,当遇到二元运算子与一元运算子一起出现时。 举个例子:
SELECT 5 ! - 6;
会被解析为:
SELECT 5 ! (- 6);
因为解译器并不知道实际的情况,所以它可能会搞错。 「!」 是一个后置运算子,并非中置运算子。 在这个例子中,要以想要的方式进行运算的话,你必须要改写为:
SELECT (5 !) - 6;
参数表达式
栏位引用
要引要一个字段的话,请使用下列的形式:
correlation.columnname
「correlation」(所属名称)是其所属表格的名称(也可能需要包含结构名),或是表格的别名(在 FROM 子句中所定义的)。
函数参数引用
$number
举个例子,有一个函数 dept 的宣告如下:
CREATE FUNCTION dept(text) RETURNS dept
AS $$ SELECT * FROM dept WHERE name = $1 $$
LANGUAGE SQL;
这里的 $1 指的是函数被呼叫时的第 1 个输入参数。
子参数表达式
一般来说,阵列表示式必须被括号起来,但如果该表示式只是一个字段或参数的引用的话,那么括号可以省略。 然后,多个子参数表示式可以连在一起使用,当你需要阵列表达多维度的概念时。 举例如下:
mytable.arraycolumn[4]
mytable.two_d_column[17][34]
$1[10:42]
(arrayfunction(a,b))[42]
字段选择
一般来说,列的表示式必须被括号起来,但如果该表示式只是一个字段或参数的引用的话,那么括号可以省略。 举例如下:
mytable.mycolumn
$1.somecolumn
(rowfunction(a,b)).col3
运算子宣告
有三种用来进行运算符宣告的语法:
expression operator expression(双元中置运算子)
operator expression(单元前置运算子)
expression operator(单元后置运算子)
运算符记号的语法规则依 4.1.3 节的说明,或是关键字 AND、OR、和 NOT,又或是如下形式的限定运算子名称:
OPERATOR(schema.operatorname)
哪些特定的运算子的使用与运算方式,端看系统与用户如何定义。 在第 9 章中会说明内建的运算子详情。
==TODO==
定义数据结构
认识数据表
有一些常用的资料类型,像是integer用于整数,numeric用于浮点数,text用于字符串,date则是日期,time是时间,而 timestamp 则同时包含日期和时间。
默认值
在表定义时,默认值接在数据类型后声明,如下所示:
CREATE TABLE products (
product_no integer,
name text,
price numeric
DEFAULT 9.99
);
默认值也可以是计算表达式,会在数据插入的同时进行运算(不是在表格建立时)。 常见的例子是 timestamp 字段,会设定一个 CURRENT_TIMESTAMP 的默认值,使其在数据插入时设定为当下的时间。 另一个例子是产生「序列数」,这在 PostgreSQL 中,通常以下列语法来表现:
CREATE TABLE products (
product_no integer
DEFAULT nextval('products_product_no_seq')
,
...
);
这里的 nextval() 函数会从序列对象取得下一个数字(参阅 9.16 节)。 这个例子也常简化为:
CREATE TABLE products (
product_no
SERIAL
,
...
);
限制条件
检查
用 CHECK 是最普遍的限制条件制定方式,它可以允许你指定某个字段必须符合某个布尔条件式的判断。 举个例子,要满足产品价格是正数的话,你可以使用这样的语法:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0)
);
你也可以让该限制条件拥有另一个名称,这样的好处是,当错误讯息发生时,你可以明确得到是哪一个限制被违反了:
CREATE TABLE products (
product_no integer,
name text,
price numeric
CONSTRAINT positive_price CHECK (price > 0)
);
一个限制条件可以参考多个字段。 例如你设定了标准价格和优惠价格,而你需要确保优惠价格一定是比标准价格要便宜的话:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0),
discounted_price numeric CHECK (discounted_price > 0),
CHECK (price > discounted_price)
);
它并不是只参考某个特定的字段,而是以逗号分隔列出所有需要遵守的条件。 栏位的定义和限制条件的定义,撰写上没有规定次序。
字段限制也可以写成表格的限制方式,不过反过来通常就不行,因为一个字段限制,指的就是只参考到语法上它所接续的字段而已。
CREATE TABLE products (
product_no integer,
name text,
price numeric,
CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0),
CHECK (price > discounted_price)
);
或等同于:
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0 AND price > discounted_price)
);
命名表限制条件和列限制条件的命名是一样的:
CREATE TABLE products (
product_no integer,
name text,
price numeric,
CHECK (price > 0),
discounted_price numeric,
CHECK (discounted_price > 0),
CONSTRAINT valid_discount CHECK (price > discounted_price)
);
应该要注意的是,检查限制条件是否成立,端看条件表示式在运算后是真值(true)还是空值(null)。 因为当有算子是空值时,多数的运算结果都是空值,所以可能会有空值产生在想要限制条件的字段之中。 要确保字段中不会出现空值的话,请参阅下一段的说明。
限制无空值
限制无空值只要以下方的语法设定,就可以限制字段不得存在空值的输入:
CREATE TABLE products (
product_no integer NOT NULL,
name text NOT NULL,
price numeric
);
限制唯一性
限制唯一性,确保在某个字段或某一群字段的数据,是在该表格中独一无二的。 语法如下:
CREATE TABLE products (
product_no integer UNIQUE,
name text,
price numeric
);
这是字段限制的语法。 而:
CREATE TABLE products (
product_no integer,
name text,
price numeric,
UNIQUE (product_no)
);
则是表格限制的写法。
如果想要限制一组的字段的唯一性的话,请使用表格限制的语法,字段以逗号分隔:
CREATE TABLE example (
a integer,
b integer,
c integer,
UNIQUE (a, c)
);
这表示这些字段所包含的内容组合,在整个表格中是具有唯一性的,但任何一个字段本身并不一定具备唯一性。
你可以命名唯一性的限制条件,语法如下:
CREATE TABLE products (
product_no integer CONSTRAINT must_be_different UNIQUE,
name text,
price numeric
);
加入唯一性的限制条件,将会自动建立一个具唯一性的 B-tree 索引,其包含的字段就如限制条件中所条列的字段。 这样唯一性限制的语法并不能只限制某部份列的唯一性,但如果使用”部份索引 (partial index) 」的话就可以做到。
一般来说,唯一性被违反的情况是,所限制的字段在表格中,有超过一列的数据是相等的。 不过,空值并不会被计算在内。 这表示说,即使设定了唯一性的限制,在被限制的字段中,还是有可能会有多个列的数据是空值。 这个设计源自 SQL 标准,但听说有其他的 SQL 数据库并不是这样的规则。 所以,如果要移植这个语法到其他数据库的话,要注意这项设计有无差异。
主键
主键的意思是,某一个字段或某一群字段,在整个表格中,其每一列的组合都是唯一的,且有宣告唯一性的限制条件,并且也包含了非空值的条件(UNIQUE 及 NOT NULL)。
所以,下面的两种语法对数据的意义相同:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE products (
product_no integer UNIQUE NOT NULL,
name text,
price numeric
);
主键也可以包含多个字段,语法和宣告唯一限制条件类似:
CREATE TABLE example (
a integer,
b integer,
c integer,
PRIMARY KEY (a, c)
);
加入主键时,会自动建立一个具唯一性的 B-tree 索引,范围为 PRIMARY KEY 语法所定义的字段,并且会强制将这些字段设定为非空值(NOT NULL)。
一个表格只能有一个主键。 (你可以使用 UNIQUE 及 NOT NULL 设置多个同样的限制条件,在功能上几乎是相同的,但只能有一组条件是由 PRIMARY KEY 所定义。 )
外部键
外部键指的是某个字段或某一群字段的内容,必须在另一个表格相对字段之中,存在相同内容的资料。 我们会说这样的行为是在维护两个表格之间的关连性。
就使用我们已经使用多次的产品表格吧:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
让我们假设你有一个表格用来储存这些产品的订单,我们要确保这些订单内的产品确实存在。 所以我们定义一个外部键来关连订单的表格和产品的表格:
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products (product_no),
quantity integer
);
订单表格是引用表格(referencing table),而产品表格是参考表格(referenced table)。 相对地,字段也称为引用字段(referencing columns)及参考字段(referenced columns)。
你可以将这个语法简化为:
CREATE TABLE orders (
order_id integer PRIMARY KEY,
product_no integer REFERENCES products,
quantity integer
);
外部键也可以参考一组字段。 一般来说,这样要写成表格限制条件形式,如下:
CREATE TABLE t1 (
a integer PRIMARY KEY,
b integer,
c integer,
FOREIGN KEY (b, c) REFERENCES other_table (c1, c2)
);
一个表格可以有许多个外部键,这用于表格之间多对多的关系。 例如你有一些表格记录了很多产品和订单,但现在你要让每一笔订单也可以订购多项产品(这在先前的语法并不允许)。 你也许可以试试这个表格宣告:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products,
order_id integer REFERENCES orders,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
注意到这里的主键和外部键是重复的。
我们知道外部键不允许没有关连到产品的订单,但如果企图移除一个有订单的产品会如何呢? SQL 有几个选项让你直觉进行这项操作:
要描绘这些情况,让我们建立如上需求的多对多关连的结构:当某人要移除一个有订单的产品(以 order_items 关连)时,我们不允许执行。 而如果某人移除了一笔订单,订单内的项目也会同步被移除:
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text,
...
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT,
order_id integer REFERENCES orders ON DELETE CASCADE,
quantity integer,
PRIMARY KEY (product_no, order_id)
);
引用和同步删除有两个常见的作法。 用「RESTRICT」防止参考的数据被删除; 「NO ACTION」表示当限制条件被违反时,引用字段的数据仍会留存,然后回传错误消息,如果未指定处理方式的话,这会是预设的行为(这两个语法根本上的不同是「NO ACTION」允许延迟检查到交易事务的最后,而「RESTRICT」则不会。 );
「CASCADE」指的是当参考的资料列被删除时,引用的数据栏也会同步被删除。 删除时还有两个其他的选项:SET NULL 和 SET DEFAULT,表示引用的数据会被更新为空值或其默认值。 注意到,这并不是说你就可以违反限制条件。 举个例来说,如果使用了 SET DEFAULT,但默认值却违反了外部键的限制,这个操作将会失败。
类似的于 ON DELETE 的情况是 ON UPDATE,也就是在参考字段的数据内容被更新时的情况。 可以设定的动作关键字是相同的。 在这个情况的 CASCADE 指的就是更新参考字段的数据内容时,引用字段的内容也会同步被更新为相同的内容。
除外宣告
除外宣告要确保的是,如果任意两个数据列在指定的字段或表示式被比较时,用于特定的运算子,至少有一个比较会回传假(false)或空值(null)。 语法如下:
CREATE TABLE circles (
c circle,
EXCLUDE USING gist (c WITH &&)
);
详情请参考 CREATE TABLE 中,CONSTRAINT 到 EXCLUDE 的段落。
选择除外宣告时,将会自动建立相对应的索引。
表格变更
加入字段
要添加新列,请使用下面命令 :
ALTER TABLE products ADD COLUMN description text;
这个新的字段默认会以默认值填入(如果你没有使用 DEFAULT 子句来宣告的话,那会使用 NULL)。
你也可以在新增同时建立限制条件:
ALTER TABLE products ADD COLUMN description text CHECK (description <> '');
事实上,所有在 CREATE TABLE 的选项都可以在这里使用。 要记得的是,默认值必须要符合限制条件的设定,否则这个字段会无法加入。 顺带一提的是,你也可以随后再加入限制条件(随后说明),在你更新好新的字段资料内容后。
删除字段
要删除一个字段,请使用下列命令 :
ALTER TABLE products DROP COLUMN description;
不论资料在该字段是否消灭,表格的限制条件都会同步再次启动检查。 所以,如果字段是被外部键所参考的话,PostgreSQL 不会就这样移除它。 你可以宣告同步删去与此字段相关的物件,加上 CASCADE:
ALTER TABLE products DROP COLUMN description CASCADE;
加入限制条件
要加入限制条件,请使用表格限制条件的语法,例如:
ALTER TABLE products ADD CHECK (name <> '');
ALTER TABLE products ADD CONSTRAINT some_name UNIQUE (product_no);
ALTER TABLE products ADD FOREIGN KEY (product_group_id) REFERENCES product_groups;
要加入 NOT NULL 限制条件的话,就不能写成表格的限制条件,请使用这样的语法:
ALTER TABLE products ALTER COLUMN product_no SET NOT NULL;
加入的限制条件会立即开始检查,所以当下的资料内容必须要能符合条件才能加入成功。
移除限制条件
要移除限制条件,你需要先知道它的名称。 如果你在宣告时有命名的话,那就使用那个名称,否则你得找出系统自动命名的名称。 其所使用的指令为「\d tablename」,会列出表格相关的信息。 或使用其他的数据库工具应该也可以找到它。 找到后请使用下列命令来删除限制条件 :
ALTER TABLE products DROP CONSTRAINT some_name;
如果你的限制条件名称像是「$2」这样的,不要忘记使用双引号括住,使其可以正确地被识别为是名称。 )
在移除字段时,你需要加入 CASCADE,如果你需要同步移除相关的限制条件的话。 像是外部键就会依赖另一个唯一性限制或主键的限制条件。
下面这可以用在删除 NOT NULL 限制的字段:
ALTER TABLE products ALTER COLUMN product_no DROP NOT NULL;
(记得 NOT NULL 是没有名称的。 )
改变默认值
要设置新的字段默认值,请使用下面命令 :
ALTER TABLE products ALTER COLUMN price SET DEFAULT 7.77;
注意这并不会影响到已经存在的数据,只有随后新增的数据才会使用。
要删除默认值,请使用:
ALTER TABLE products ALTER COLUMN price DROP DEFAULT;
这个指令会把默认值设为空值。 因为默认值本来就设为空值,所以即使删去一个未设定预设值字段的默认值,也不会是一种错误。
改变字段数据类型
要更改字段成为另一个数据类型,请使用下列命令:
ALTER TABLE products ALTER COLUMN price TYPE numeric(10,2);
这只有在字段内容可以被自动转换型别时才会成功。 如果存在比较复杂的转换时,你需要加上 USING 子句来指示如何转换数据内容。
PostgreSQL 会企图转换字段预设值到任何新的类型,而所有的限制条件也会启动检查机制。 但这些转换可能会失败,也可以产生意外的结果。 比较好的作法是,先移除限制条件,再变更资料型别,最后再重新加入适当调整后的限制条件。
更改字段名称
要更改字段名称 :
ALTER TABLE products RENAME COLUMN product_no TO product_number;
更改表格名称
要更改表的名称 :
ALTER TABLE products RENAME TO items;
权限
当一个数据库对象被创建时,它会先指定访问权限给所有者,而所有者一般来说就是执行建立指令的用户。
有很多不同种类的权限:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE。
修改和移除一个数据库对象,是只有所有者才具备的权力。
要把一个对象被指派给一个新的所有者的话,使用该物件的 ALTER 指令,例如:ALTER TABLE。
要进行授权行为的话,请使用 GRANT 指令。 举例来说,如果 joe 是一个用户,而 accounts 是一个表格,要让他可以获得更新表格资料的权力:
GRANT UPDATE ON accounts TO joe;
使用 ALL 的权限,就代表授权所有可设定的权限。
有一个特别的用户是 PUBLIC,代表的是系统内的所有用户。 当数据库内有很多用户时,可以制定「群组(group)」来简化管理。 这部分详细的说明请参阅第21章。
要删除权限,请使用 REVOKE 命令 :
REVOKE ALL ON accounts FROM PUBLIC;
对象所有者的特殊权限(例如DROP、GRANT、REVOKE… 等)都是和所有者一起设定,而无法单独授权。 不过,所有者可以选择移除自己的权限,例如建立一个只读的表格,让自己和其他人一样。
回到前面所说的,只有对象的所有者(或超级用户)可以变更该对象的权限。 然而,也可以使用「with grant option」让另一个用户可以代授权给其他用户。 不过如果这个「grant option」被移除时,所有被代授权的用户都会同时丧失该权限。 更详细的说明请参阅 GRANT 及 REVOKE 说明页面。
==TODO==
数据类型
PostgreSQL 内置一套丰富的数据类型供用户使用。 用户也可以使用 CREATE TYPE 指令让 PostgreSQL 增加新的数据类型。
| 名字 | 别名 | 描述 |
|---|---|---|
bigint |
int8 |
有符号的8字节整数 |
bigserial |
serial8 |
自动增长的8字节整数 |
bit [ (*n*) ] |
定长位串 | |
bit varying [ (*n*) ] |
varbit |
变长位串 |
boolean |
bool |
逻辑布尔值(真/假) |
box |
平面上的普通方框 | |
bytea |
二进制数据(“字节数组”) | |
character [ (*n*) ] |
char [ (*n*) ] |
定长字符串 |
character varying [ (*n*) ] |
varchar [ (*n*) ] |
变长字符串 |
cidr |
IPv4或IPv6网络地址 | |
circle |
平面上的圆 | |
date |
日历日期(年、月、日) | |
double precision |
float8 |
双精度浮点数(8字节) |
inet |
IPv4或IPv6主机地址 | |
integer |
int, int4 |
有符号4字节整数 |
interval [ *fields* ] [ (*p*) ] |
时间段 | |
json |
文本 JSON 数据 | |
jsonb |
二进制 JSON 数据,已分解 | |
line |
平面上的无限长的线 | |
lseg |
平面上的线段 | |
macaddr |
MAC(Media Access Control)地址 | |
macaddr8 |
MAC (Media Access Control) 地址 (EUI-64 格式) | |
money |
货币数量 | |
numeric [ (*p*, *s*) ] |
decimal [ (*p*, *s*) ] |
可选择精度的精确数字 |
path |
平面上的几何路径 | |
pg_lsn |
PostgreSQL日志序列号 | |
point |
平面上的几何点 | |
polygon |
平面上的封闭几何路径 | |
real |
float4 |
单精度浮点数(4字节) |
smallint |
int2 |
有符号2字节整数 |
smallserial |
serial2 |
自动增长的2字节整数 |
serial |
serial4 |
自动增长的4字节整数 |
text |
变长字符串 | |
time [ (*p*) ] [ without time zone ] |
一天中的时间(无时区) | |
time [ (*p*) ] with time zone |
timetz |
一天中的时间,包括时区 |
timestamp [ (*p*) ] [ without time zone ] |
日期和时间(无时区) | |
timestamp [ (*p*) ] with time zone |
timestamptz |
日期和时间,包括时区 |
tsquery |
文本搜索查询 | |
tsvector |
文本搜索文档 | |
txid_snapshot |
用户级别事务ID快照 | |
uuid |
通用唯一标识码 | |
xml |
XML数据 |
数字类型
| 名字 | 存储尺寸 | 描述 | 范围 |
|---|---|---|---|
smallint |
2字节 | 小范围整数 | -32768 to +32767 |
integer |
4字节 | 整数的典型选择 | -2147483648 to +2147483647 |
bigint |
8字节 | 大范围整数 | -9223372036854775808 to +9223372036854775807 |
decimal |
可变 | 用户指定精度,精确 | 最高小数点前131072位,以及小数点后16383位 |
numeric |
可变 | 用户指定精度,精确 | 最高小数点前131072位,以及小数点后16383位 |
real |
4字节 | 可变精度,不精确 | 6位十进制精度 |
double precision |
8字节 | 可变精度,不精确 | 15位十进制精度 |
smallserial |
2字节 | 自动增加的小整数 | 1到32767 |
serial |
4字节 | 自动增加的整数 | 1到2147483647 |
bigserial |
8字节 | 自动增长的大整数 | 1到9223372036854775807 |
货币类型
| 名字 | 存储尺寸 | 描述 | 范围 |
|---|---|---|---|
money |
8 bytes | 货币额 | -92233720368547758.08到+92233720368547758.07 |
字符类型
| 名字 | 描述 |
|---|---|
character varying(*n*), varchar(*n*) |
有限制的变长 |
character(*n*), char(*n*) |
定长,空格填充 |
text |
无限变长 |
二进制类型
| 名字 | 存储尺寸 | 描述 |
|---|---|---|
bytea |
1或4字节外加真正的二进制串 | 变长二进制串 |
日期时间类型
| 名字 | 存储尺寸 | 描述 | 最小值 | 最大值 | 解析度 |
|---|---|---|---|---|---|
timestamp [ (*p*) ] [ without time zone ] |
8字节 | 包括日期和时间(无时区) | 4713 BC | 294276 AD | 1微秒 / 14位 |
timestamp [ (*p*) ] with time zone |
8字节 | 包括日期和时间,有时区 | 4713 BC | 294276 AD | 1微秒 / 14位 |
date |
4字节 | 日期(没有一天中的时间) | 4713 BC | 5874897 AD | 1日 |
time [ (*p*) ] [ without time zone ] |
8字节 | 一天中的时间(无日期) | 00:00:00 | 24:00:00 | 1微秒 / 14位 |
time [ (*p*) ] with time zone |
12字节 | 一天中的时间(不带日期),带有时区 | 00:00:00+1459 | 24:00:00-1459 | 1微秒 / 14位 |
interval [ *fields* ] [ (*p*) ] |
16字节 | 时间间隔 | -178000000年 | 178000000年 | 1微秒 / 14位名字 |
布尔类型
| 名字 | 存储字节 | 描述 |
|---|---|---|
boolean |
1字节 | 状态为真或假 |
枚举类型
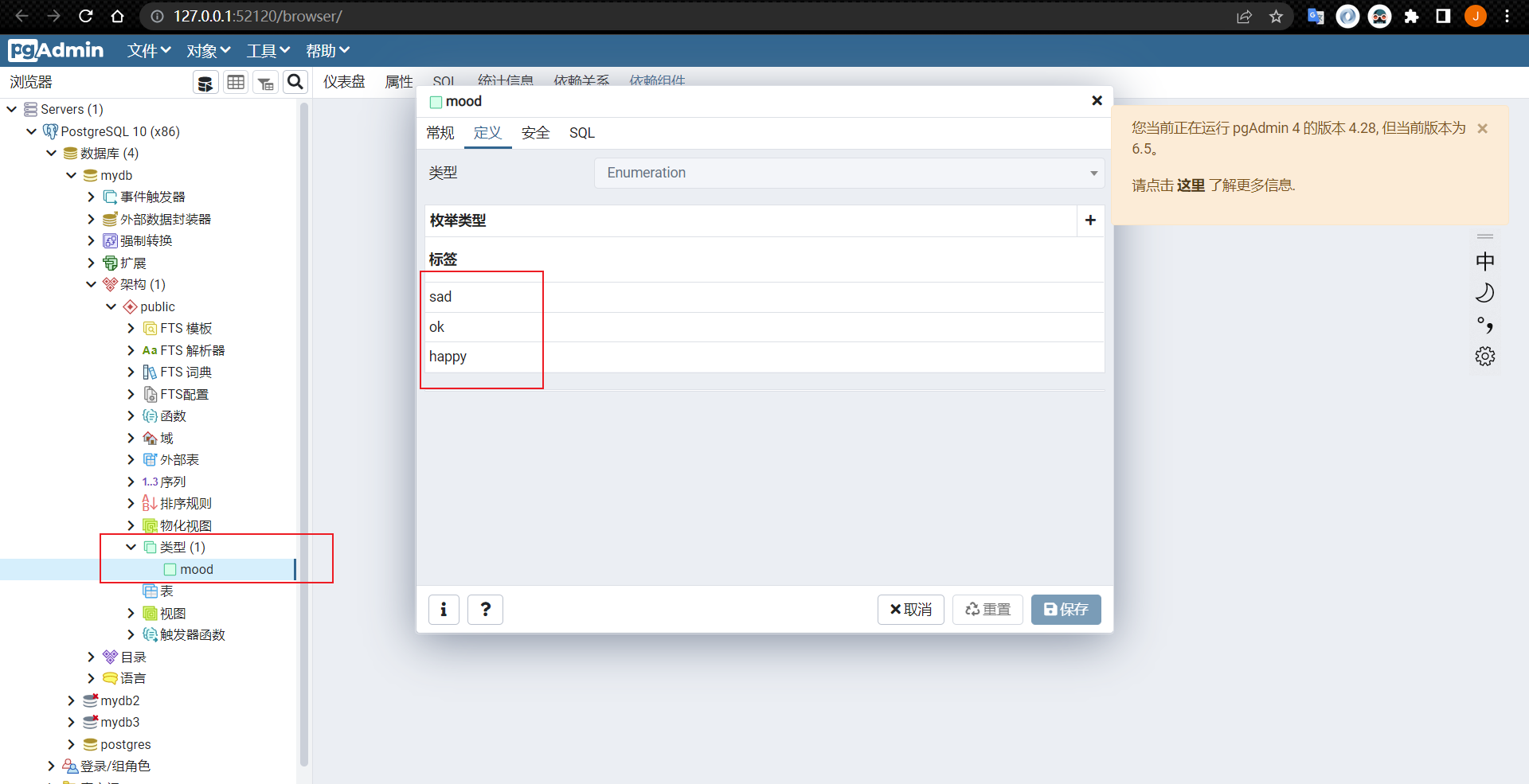
枚举类型可以使用CREATE TYPE命令创建,例如:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
一旦被创建,枚举类型可以像很多其他类型一样在表和函数定义中使用:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
name | current_mood
------+--------------
Moe | happy
(1 row)
几何类型
| 名字 | 存储尺寸 | 表示 | 描述 |
|---|---|---|---|
point |
16字节 | 平面上的点 | (x,y) |
line |
32字节 | 无限长的线 | {A,B,C} |
lseg |
32字节 | 有限线段 | ((x1,y1),(x2,y2)) |
box |
32字节 | 矩形框 | ((x1,y1),(x2,y2)) |
path |
16+16n字节 | 封闭路径(类似于多边形) | ((x1,y1),…) |
path |
16+16n字节 | 开放路径 | [(x1,y1),…] |
polygon |
40+16n字节 | 多边形(类似于封闭路径) | ((x1,y1),…) |
circle |
24字节 | 圆 | <(x,y),r> (center point and radius) |
网络地址类型
| 名字 | 存储尺寸 | 描述 |
|---|---|---|
cidr |
7或19字节 | IPv4和IPv6网络 |
inet |
7或19字节 | IPv4和IPv6主机以及网络 |
macaddr |
6字节 | MAC地址 |
macaddr8 |
8 字节 | MAC 地址 (EUI-64 格式) |
位串类型
位串就是一串 1 和 0 的串。它们可以用于存储和可视化位掩码。我们有两种类型的 SQL 位类型:bit(*n*)和bit varying(*n*),其中 *n*是一个正整数。
bit类型的数据必须准确匹配长度*n; 试图存储短些或者长一些的位串都是错误的。bit varying数据是最长n*的变长类型,更长的串会被拒绝。写一个没有长度的bit等效于 bit(1),没有长度的bit varying意味着没有长度限制。
文本搜索类型
一个tsvector值是一个排序的可区分词位的列表,词位是被正规化合并了同一个词的不同变种的词(详见第 12 章)。排序和去重是在输入期间自动完成的,如下例所示:
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
一个tsquery值存储要用于搜索的词位,并且使用布尔操作符&(AND)、|(OR)和!(NOT)来组合它们,还有短语搜索操作符<->(FOLLOWED BY)。也有一种 FOLLOWED BY 操作符的变体<*N*>,其中*N*是一个整数常量,它指定要搜索的两个词位之间的距离。<->等效于<1>。
圆括号可以被用来强制对操作符分组。如果没有圆括号,!(NOT)的优先级最高,其次是<->(FOLLOWED BY),然后是&(AND),最后是|(OR)。
这里有一些例子:
SELECT 'fat & rat'::tsquery;
tsquery
---------------
'fat' & 'rat'
SELECT 'fat & (rat | cat)'::tsquery;
tsquery
---------------------------
'fat' & ( 'rat' | 'cat' )
SELECT 'fat & rat & ! cat'::tsquery;
tsquery
------------------------
'fat' & 'rat' & !'cat'
UUID类型
一个UUID被写成一个小写十六进制位的序列,该序列被连字符分隔成多个组:首先是一个8位组,接下来是三个4位组,最后是一个12位组。总共的32位(十六进制位)表示了128个二进制位。一个标准形式的UUID类似于:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
XML类型
创建XML值
要从字符数据中生成一个xml类型的值,可以使用函数xmlparse:
XMLPARSE ( { DOCUMENT | CONTENT } value)
例子:
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>')
XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>')
然而根据SQL标准这是唯一将字符串转换为XML值的方法,PostgreSQL特有的语法:
xml '<foo>bar</foo>'
'<foo>bar</foo>'::xml
也可以被使用。
JSON 类型
JSON 数据类型是用来存储 JSON(JavaScript Object Notation) 数据的。这种数据也可以被存储为text,但是 JSON 数据类型的 优势在于能强制要求每个被存储的值符合 JSON 规则。
数组类型
为了展示数组类型的使用,我们创建这样一个表:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
如上所示,一个数组数据类型可以通过在数组元素的数据类型名称后面加上方括号([])来命名。上述命令将创建一个名为sal_emp的表,它有一个类型为text的列(name),一个表示雇员的季度工资的一维integer类型数组(pay_by_quarter),以及一个表示雇员每周日程表的二维text类型数组(schedule)。
CREATE TABLE的语法允许指定数组的确切大小,例如:
CREATE TABLE tictactoe (
squares integer[3][3]
);
复合类型
这里有两个定义复合类型的简单例子:
CREATE TYPE complex AS (
r double precision,
i double precision
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
该语法堪比CREATE TABLE,不过只能指定域名和类型,当前不能包括约束(例如NOT NULL)。注意AS关键词是必不可少的,如果没有它,系统将认为用户想要的是一种不同类型的CREATE TYPE命令,并且你将得到奇怪的语法错误。
定义了类型之后,我们可以用它们来创建表:
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
或者函数:
CREATE FUNCTION price_extension(inventory_item, integer) RETURNS numeric
AS 'SELECT $1.price * $2' LANGUAGE SQL;
SELECT price_extension(item, 10) FROM on_hand;
只要你创建了一个表,也会自动创建一个复合类型来表示表的行类型,它具有和表一样的名称。例如,如果我们说:
CREATE TABLE inventory_item (
name text,
supplier_id integer REFERENCES suppliers,
price numeric CHECK (price > 0)
);
范围类型
PostgreSQL 带有下列内建范围类型:
int4range—integer的范围int8range—bigint的范围numrange—numeric的范围tsrange—不带时区的 timestamp的范围tstzrange—带时区的 timestamp的范围daterange—date的范围
此外,你可以定义自己的范围类型,详见CREATE TYPE。
例子
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- 包含
SELECT int4range(10, 20) @> 3;
-- 重叠
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
-- 抽取上界
SELECT upper(int8range(15, 25));
-- 计算交集
SELECT int4range(10, 20) * int4range(15, 25);
-- 范围为空吗?
SELECT isempty(numrange(1, 5));
对象标识符类型
==TODO==
pg_lsn类型 Type
pg_lsn数据类型可以被用来存储 LSN(日志序列号)数据,LSN 是一个指向 WAL 中的位置的指针。这个类型是XLogRecPtr的一种表达并且是 PostgreSQL的一种内部系统类型。
伪类型
| 名字 | 描述 |
|---|---|
any |
表示一个函数可以接受任意输入数据类型。 |
anyelement |
表示一个函数可以接受任意数据类型(参见第 37.2.5 节)。 |
anyarray |
表示一个函数可以接受任意数组数据类型(参见第 37.2.5 节) |
anynonarray |
表示一个函数可以接受任意非数组数据类型(参见第 37.2.5 节)。 |
anyenum |
表示一个函数可以接受任意枚举数据类型(参见第 37.2.5 节和第 8.7 节)。 |
anyrange |
表示一个函数可以接受任意范围数据类型(参见第 37.2.5 节和第 8.17 节)。 |
cstring |
表示一个函数接受或者返回一个非空结尾的C字符串。 |
internal |
表示一个函数接受或返回一个服务器内部数据类型。 |
language_handler |
一个被声明为返回language_handler的过程语言调用处理器。 |
fdw_handler |
一个被声明为返回fdw_handler的外部数据包装器处理器。 |
index_am_handler |
一个被声明为返回index_am_handler索引访问方法处理器。 |
tsm_handler |
一个被声明为返回tsm_handler的表采样方法处理器。 |
record |
标识一个接收或者返回一个未指定的行类型的函数。 |
trigger |
一个被声明为返回trigger的触发器函数。 |
event_trigger |
一个被声明为返回event_trigger的事件触发器函数。 |
pg_ddl_command |
标识一种对事件触发器可用的 DDL 命令的表达。 |
void |
表示一个函数不返回值。 |
unknown |
标识尚未解析的类型,例如,未装饰的字符串文字。 |
opaque |
一种已被废弃的类型名称,以前它用于实现大多数以上的目的。 |