PostgreSQL
创建一个数据库
在D:\ProgramFiles(x86)\PostgreSQL\10\bin目录下打开cmd,输入:
create -U 用户 数据库名
如下使用默认用户postgres,创建数据库mydb3,输入口令等待创建成功。
C:\Users\zichen>createdb -U postgres mydb3
口令:
C:\Users\zichen>
或者把D:\ProgramFiles(x86)\PostgreSQL\10\bin添加到环境变量Path中,就可以随时随地打开cmd使用createdb命令。
备份
SQL转储
- 默认情况下,psql脚本在遇到一个SQL错误后会继续执行。
- 可以设置
ON_ERROR_STOP变量来运行psql,这将使psql在遇到SQL错误后退出并返回状态3。你将只能得到一个部分恢复的数据库。 - 你可以指定让整个恢复作为一个单独的事务运行,可以通过向psql传递
-1或--single-transaction命令行选项来指定。
文件系统级备份
另外一种备份策略是直接复制PostgreSQL用于存储数据库中数据的文件。
查询数据库对应的文件夹名:
select oid, datname from pg_database ;数据库文件布局:PostgreSQL: 文档: 8.4: 数据库文件布局
为了得到一个可用的备份,数据库服务器必须被关闭。在恢复数据之前你也需要关闭服务器。
SIGTERM
这是智能关闭模式。在接收SIGTERM后, 服务器将不允许新连接,但是会让现有的会话正常结束它们的工作。仅当所有的会话终止后它才关闭。
包含在这些文件中的信息只有配合提交日志文件(pg_xact/*)才有用,提交日志文件包含了所有事务的提交状态。一个表文件只有和这些信息一起才有用。当然也不可能只恢复一个表及相关的pg_xact数据,因为这会导致数据库集簇中所有其他表变得无用。因此文件系统备份只适合于完整地备份或恢复整个数据库集簇。
另一种文件系统备份方法是创建一个数据目录的“一致快照”。
典型的过程是创建一个包含数据库的卷的“冻结快照”,然后从该快照复制整个数据目录(如上,不能是部分复制)到备份设备,最后释放冻结快照。即使在数据库服务器运行时,这种方式也有效。还有一种选择是使用rsync来执行一次文件系统备份
其做法是先在数据库服务器运行时执行rsync,然后关闭数据库服务器足够长时间来做一次rsync --checksum(--checksum是必需的,因为rsync的文件修改 时间粒度只能精确到秒)。这种方法允许在最小停机时间内执行一次文件系统备份。
连续归档
在任何时间,PostgreSQL在数据集簇目录的pg_wal/子目录下都保持有一个预写式日志(WAL)。D:\ProgramFiles(x86)\PostgreSQL\10\data\pg_wal,这个日志存在的目的是为了保证崩溃后的安全:如果系统崩溃,可以“重放”从最后一次检查点以来的日志项来恢复数据库的一致性。
我们可以把一个文件系统级别的备份和WAL文件的备份结合起来。
需要恢复时,我们先恢复文件系统备份,然后从备份的WAL文件中重放来把系统带到一个当前状态。这种方法比之前的方法管理起来要更复杂,但是有其显著的优点:
25.3. 连续归档和时间点恢复(PITR) (postgres.cn)
建立WAL归档
cmd命令
D:\ProgramFiles(x86)\PostgreSQL\10\bin> pg_dump -U postgres hjy //备份数据库hjy,使用用户postgres登录
Other
PostgreSQL文档
介绍
PostgreSQL 由伯克莱大学公开其源代码所诞生,它支持了大多数的标准 SQL 语法。
同时,PostgreSQL 也支持让用户能以自己的方式进行扩充。 比如通过添加:
- 数据类型(data types)
- 函数(functions)
- 操作(operators)
- 聚合函数(aggregate functions)
- 索引方法(index methods)
- 过程语言(procedural languages)
PostgreSQL 现在是世界上最先进的开源数据库系统。
基础
PostgreSQL 采用了主从式架构(client/server)。
如同一般的主从式架构,客户端与伺服端可以是两台不同的主机,而他们透过 TCP/IP 的网路协议沟通。 你应该将这个观念谨记在心,因为某些在客户端可以被访问的文件,在伺服端可能就无法访问(或使用不同的文件名)。
PostgreSQL 服务器可以管理来自多个客户端的同时连接。 为了达到这样的功能,它会自我复制(fork)成新的执行程序,一对一地处理每一个连线。
创建数据库:createdb mydb
psql
连接数据库mydb
要离开 psql 的话,请输入 :mydb=> \q
创建表和数据
一些 PostgreSQL 语法来自于标准 SQL 的延伸。
PostgreSQL 是不分大小写字母的,包括各类关键词和描述语,除非是使用双引号括起来的文字。 (更精确地说,没有被双引号括起来的识别字,都会转为小写字母进行识别)
删除表命令:DROP TABLE tablename;
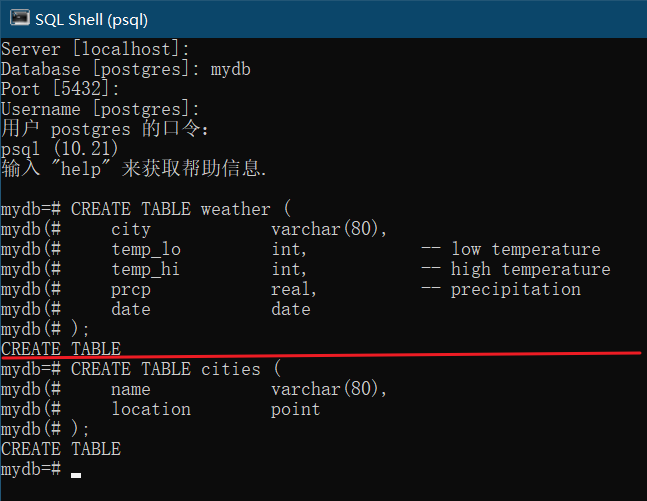
创建两张表
使用pgadmin可视化查看两张表
插入数据
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
只要不是简单的数值内容,都必须要以单引号(’)括住。
插入地理信息类型
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
地理信息类型(point type)需要有坐标组作为输入。
到目前为止,语法的使用需要你依照字段宣告的次序摆放,而另一种语法可以允许你明确地指定数据相对应的字段:
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
查询数据
查询指定字段,所有数据
SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
结果
mydb=# SELECT city, temp_lo, temp_hi, prcp, date FROM weather;
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
(1 行记录)
mydb=#
查询时回传列表中撰写一些运算表示式,而不只是简单的字段引用。注意,「AS」被用来重命名输出的字段。 (选用)
mydb=# SELECT city, (temp_hi+temp_lo)/2 AS temp_avg, date FROM weather;
city | temp_avg | date
---------------+----------+------------
San Francisco | 48 | 1994-11-27
(1 行记录)
mydb=#
增加查询条件
mydb=# SELECT * FROM weather
mydb-# WHERE city = 'San Francisco' AND prcp > 0.0;
city | temp_lo | temp_hi | prcp | date
---------------+---------+---------+------+------------
San Francisco | 46 | 50 | 0.25 | 1994-11-27
(1 行记录)
mydb=#
排序
SELECT * FROM weather
ORDER BY city, temp_lo;
去重
SELECT DISTINCT city
FROM weather;
交叉查询
mydb=# SELECT *
mydb-# FROM weather, cities
mydb-# WHERE city = name;
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
(1 行记录)
mydb=#
交叉查询会忽略数据表 weather 中未能关连的数据。
交叉查询时输出指定字段
mydb=# SELECT city, temp_lo, temp_hi, prcp, date, location
mydb-# FROM weather, cities
mydb-# WHERE city = name;
city | temp_lo | temp_hi | prcp | date | location
---------------+---------+---------+------+------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | (-194,53)
(1 行记录)
mydb=#
因为所有的字段都使用不同的名称,所以解译器会自动发现他们所属的资料表为何。 如果在两个数据表之中,存在有相同名称的字段时,你最好明确指出确定的字段:
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
交叉查询也可以写成如下的另一种形式(内部交叉查询):
mydb=# SELECT *
mydb-# FROM weather INNER JOIN cities ON (weather.city = cities.name);
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
(1 行记录)
mydb=#
我们要在查询中做的是,扫描资料表 weather,找到有所关连的每一列资料; 没有关连到的资料列,我们要填上「空值」(null)在资料表 cities 相对的字段之中。 这样的查询我们称作「外部交叉查询」(outer join)。 (先前的交叉查询为「内部交叉查询」(inner join))。 这样的查询指令如下所示(左外部交叉查询):
mydb=# SELECT *
mydb-# FROM weather LEFT OUTER JOIN cities ON (weather.city = cities.name);
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
Hayward | 37 | 54 | | 1994-11-29 | |
(2 行记录)
mydb=#
这个交叉查询,放在左侧的数据表中的资料列,一定会在结果中至少出现一次,而右侧的数据表中,则只有输出有关连到左侧数据表的资料列。 当左侧数据表的数据栏,并没有在右侧数据表中被关连到时,属于右侧数据表的字段就会被填上空值输出。
「右侧外部交叉查询」(right outer join):
mydb=# SELECT *
mydb-# FROM weather right OUTER JOIN cities ON (weather.city = cities.name);
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
(1 行记录)
mydb=#
完全外部交叉查询」(full outer join):
mydb=# SELECT *
mydb-# FROM weather FULL OUTER JOIN cities ON (weather.city = cities.name);
city | temp_lo | temp_hi | prcp | date | name | location
---------------+---------+---------+------+------------+---------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | San Francisco | (-194,53)
Hayward | 37 | 54 | | 1994-11-29 | |
(2 行记录)
mydb=#
我们也可以对同一个数据表做交叉查询,称作为「自我交叉查询」(self join)。
假设我们希望找到所有气温范围的天气数据。 所以我们需要让temp_lo及temp_hi两个字段,和其他的temp_lo及temp_high相比较。
mydb=# SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
mydb-# W2.city, W2.temp_lo AS low, W2.temp_hi AS high
mydb-# FROM weather W1, weather W2
mydb-# WHERE W1.temp_lo < W2.temp_lo
mydb-# AND W1.temp_hi > W2.temp_hi;
city | low | high | city | low | high
---------+-----+------+---------------+-----+------
Hayward | 37 | 54 | San Francisco | 46 | 50
(1 行记录)
mydb=#
汇总查询
汇总查询指的是能够把多个数据列的数据经过计算,产生单一结果的功能。举例来说, count、sum、avg(平均值)、max(最大值)、min(最小值)都是汇总查询的函式。
mydb=# SELECT max(temp_lo) FROM weather;
max
-----
46
(1 行记录)
mydb=#
如果我们想要知道,这个数值是发生在哪一个城市?
SELECT city FROM weather WHERE temp_lo = max(temp_lo); //不可以
报错:aggregate functions are not allowed in WHERE:Where 其中不允许使用聚合函数
因为 max 不能使用在 WHERE 条件式当中。 (会有这样的限制,是因为 WHERE 条件式目的是要判断有哪些数据列的数据应该被汇总计算,所以很明显地,这件事必须要在汇整计算前发生,这就产生了矛盾。 )
可以使用子查询实现:
mydb=# SELECT city FROM weather
mydb-# WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
city
---------------
San Francisco
(1 行记录)
mydb=#
汇总查询和 GROUP BY 一起使用会很方便的。 举例来说,我们可以得到每个城市所观测到的最高气温:
mydb=# SELECT city, max(temp_lo)
mydb-# FROM weather
mydb-# GROUP BY city;
city | max
---------------+-----
Hayward | 37
San Francisco | 46
(2 行记录)
mydb=#
这个查询对每个城市都输出一列的结果。 每一个汇总的结果,将整个数据表,以关连到的城市进行计算。 而我们可以进一步过滤数据内容,使用 HAVING:
mydb=# SELECT city, max(temp_lo)
mydb-# FROM weather
mydb-# GROUP BY city
mydb-# HAVING max(temp_lo) < 40;
city | max
---------+-----
Hayward | 37
(1 行记录)
mydb=#
如果限制所有temp_lo的数值必须要小于40 (WHERE temp_lo < 40)的话,也可能得到相同的结果。 最后,如果我们只关心以“S”开头的城市的话,可以这样做:
SELECT city, max(temp_lo)
FROM weather
WHERE city LIKE 'S%' -- (1)
GROUP BY city
HAVING max(temp_lo) < 40;
了解 SQL 中 WHERE 和 HAVING 之间的行为。 其根本上的差异是:WHERE 会在合并和汇总计算之前进行选择数据的动作(也就是它控制着,哪些数据需要被汇总计算); 而 HAVING 是在合并及汇整计算之后,才进行过滤数据的动作。
先前的例子当中,我们可以把城市名称的限制放在 WHERE 条件式之中,因为它不需要汇总。 这将会比放在 HAVING 条件式中更有效率,因为这样可以避免合并及汇整运算整个表格,不用浪费时间在本来就会被过滤掉的数据上。
更新修改
你可以使用 UPDATE 指令以列为单位来更新数据。 假设你发现气温的数值测量在11月28日之后都多了2度。
mydb=# UPDATE weather
mydb-# SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2
mydb-# WHERE date > '1994-11-28';
UPDATE 1
删除数据
DELETE FROM weather WHERE city = 'Hayward';
这个指令有一个应该要特别注意的情况:
DELETE FROM tablename;
没有任何限制的条件,DELETE 将会删去所有该数据表中的数据,使成为空的数据表。 数据库系统并不会在这个动作执行前和你确认!
视图
假设关连天气信息和城市位置的结果,是你的应用中特别常用的,但你并不想要每次都要输入一长串的查询语句。 那么,你可以为这个查询语句建立一个「查看表(View)」,你可以取一个名字,当你需要使用的时候,你可以把它当作一个数据表来使用:
mydb=# CREATE VIEW myview AS
mydb-# SELECT city, temp_lo, temp_hi, prcp, date, location
mydb-# FROM weather, cities
mydb-# WHERE city = name;
CREATE VIEW
mydb=#
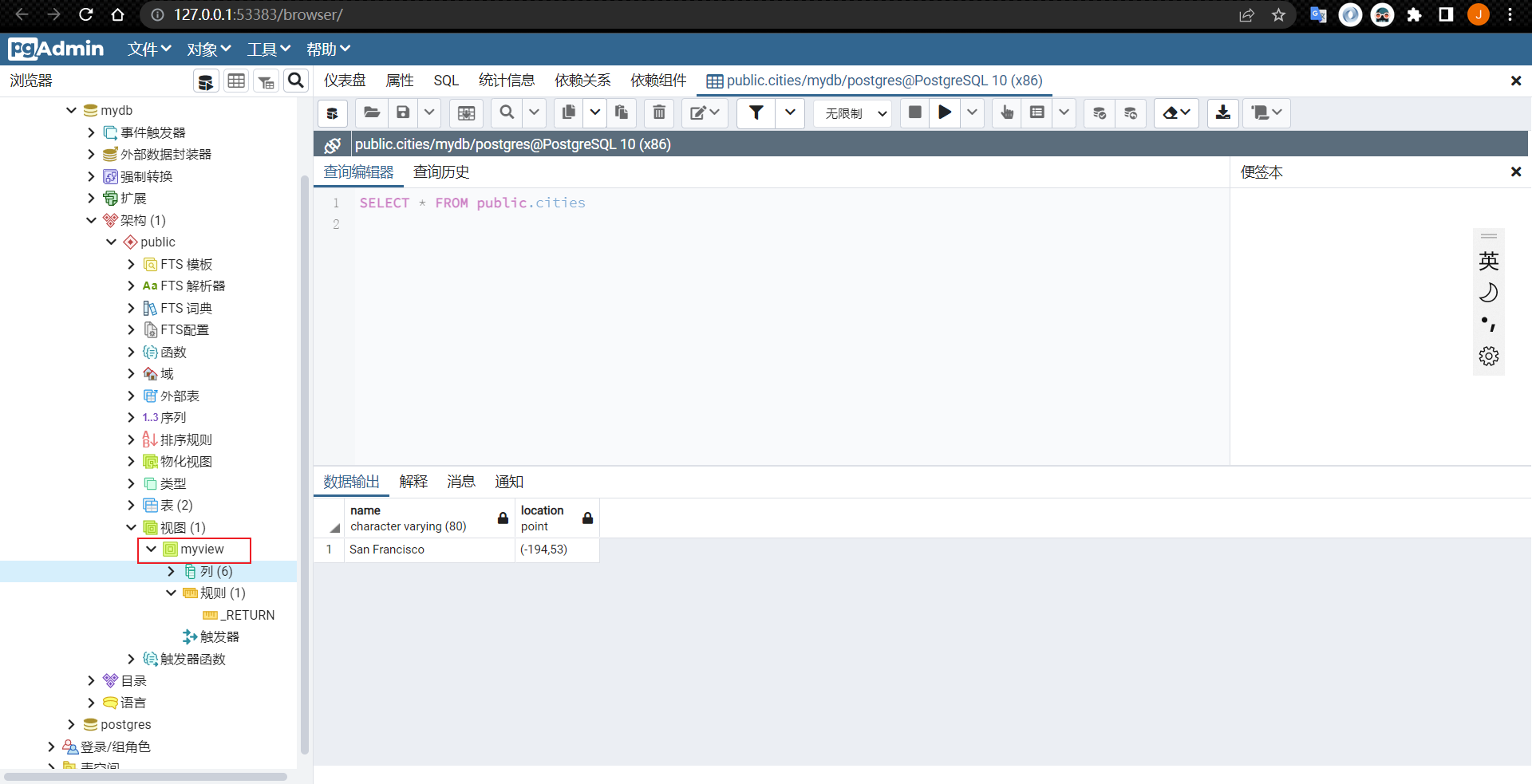
mydb=# SELECT * FROM myview;
city | temp_lo | temp_hi | prcp | date | location
---------------+---------+---------+------+------------+-----------
San Francisco | 46 | 50 | 0.25 | 1994-11-27 | (-194,53)
(1 行记录)
使用pgAdmin查看视图:
外部索引键
创建两张表
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
插入错误的数据,cities中不存在的city名字。
INSERT INTO weather VALUES ('Berkeley', 45, 53, 0.0, '1994-11-28');
报错:
ERROR: insert or update on table "weather" violates foreign key constraint "weather_city_fkey"
DETAIL: Key (city)=(Berkeley) is not present in table "cities".
错误:在表“weather”上插入或更新违反外键约束“weather_city_fkey”
详细信息:键(城市)=(’Berkeley’)不在表“城市”中。
外部索引键或简称外部键(foreign key)的行为可以让你的应用程序变得容易调整。正确地使用外部索引键,可以改善数据库应用程序的质量。
事务交易安全
交易(Transaction),是所有数据库的基础概念。 基本上来说,一个交易指的是,一系列的执行步骤包裹在一起,其结果只有全部成功或全部失败两种情况的操作行为。